Section 1: Preliminary information
Proteins are polypeptides of amino-acids: Proteins direct virtually all activities of the cell and have a wide variety of functions (information transmission, chemical reaction catalysis, cellular transport, infection defense, etc.). Proteins are polymers synthesized from 20 different amino acids. Each amino acid consists of a carbon atom (called the α carbon) bonded to a carboxyl group (COO–), an amino group (NH3+), a hydrogen atom, and a distinctive side chain — the side chains determine the chemical properties of the amino acid, and contribute to the overall structure and function of the protein. [1] Amino acids are joined together by peptide covalent bonds between the α carboxyl group of one amino acid and the α amino group of a second. Polypeptides are linear chains of amino acids, usually hundreds or thousands of amino acids in length. Each polypeptide chain has two distinct ends, one terminating in an amino group (the amino, or N, terminus) and the other in a carboxyl group (carboxy, or C, terminus).

Amino acids and the protein structure: The amino acid sequence eventually determines the protein’s 3D shape; the chemistry of the side chains is critical to protein structure because these side chains can bond with one another to hold a length of protein in a certain shape or conformation by nature of their properties — charges (leading to ionic bonds), polarity (leading to hydrogen bonds), hydrophobic nature (leading to Van der Waals forces). Although these side chain interactions are largely non-covalent, they are strong enough to guide where the bends and folds and rotations occur in that protein. [2] There are 4 levels of organization of protein structure (a) The protein primary structure is considered it’s amino acid sequence. (b) Its secondary structure refers to the local arrangements of the chain in space — common examples include alpha helix and beta sheets (c) The tertiary structure is its overall three-dimensional shape, once all the secondary structure elements have folded together among each other (b) The quatenary structure is the assembly of multiple polypeptide chain sub-units interacting with each other. [3]
Challenges and common methods of Protein Structure Prediction: The C-N bond (peptide bond) has a partial double bond character and remains relatively fixed; this angle () is usually 180 and has little significance in polypeptide folding. There are two essential torsion (rotation) angles in the polypeptide chain, also called Ramachandran angles. These angles describe the rotations of the polypeptide backbone around the bonds between N-Cα (called Phi, φ) and Cα-C (called Psi, ψ) and essentially determine the fold of the protein (more on torsion angles and side chain angles later). The protein folding problem is highly challenging because of the sheer number of possible conformations of the φ and ψ of each monomer of the polypeptide chain. Older methods of modelling the physical interactions using thermodynamic or molecular stimulations tend to be computationally intractible. Other current methods include analysis of pairwise evolutionary correlations and homology (~similarity) with solved proteined structures, however, these fall short on level of accuracy required for widespread adoption and utility.
Section 2: Enter Alphafold2!
Alphafold2’s neural network architectures and training procedure led to a greatly improved 3D structure prediction in the CASP14 challenge, beating the next best solution by a large margin[4]. The rest of the article is a step-by-step overview of Alphafold2, based on the paper and the supplementary section, as well as several fantastic blogs referenced below. [5][6][7]
Bird’s eye view of the overall architecture: Alphafold2 is a deep learning based architecture that predicts the 3D protein structure to a high degree of accuracy.
- It’s primary input is the sequence of the protein (along with the MSA and relevant templates).
- In the Evoformer trunk of the network, two types of rich representations are created and refined (a) A representation of the protein sequence in relation to other homologous sequences (MSA representation) and (b) A representation of the protein sequence that describes the relationship of each amino-acid with every other amino acid in the sequence (pairwise representation)
- The structure module uses these representations to refine and produce co-ordinate locations of the backbone amino acids and the backbone + side chain torsion angles.
- The network is trained end-to-end using the final FAPE loss and several intermediate/auxillary loss terms

Section 2.1 Inputs and Processing
Bird’s eye view of inputs and processing: The input to the network is the primary protein sequence and the label is the 3D co-ordinates of the sequence structure.
- Along with the primary input sequence, the network also uses Multiple Sequence Alignments (MSA) of homologous proteins and structural templates of the homologous proteins.
- At the end of the input module, two types of representations are created for further processing — the MSA representation, and the pairwise representation.
2.1.1 Primary Input Data Sources
The models were trained on the PDB (ProteinDataBank) database that contains protein sequences and their groundtruth protein structures. The inputs to the network during training are —
- The primary protein sequence from Protein Data Bank (input) and 3D atom co-ordinates of homologous sequences from Protein Data Bank (label)
- Genetic search for Multiple Sequence Alignments: For each train sequence a Multiple sequence alignment (MSA) with evolutionarily related (homologous) proteins is fetched. Intuitively, MSAs help deduce information about protein structure — for example, if mutations observed at two points (sequentially far away from each other) are highly correlated, chances are they’re actually physically close to one another when folded. This is explained well here. To find the MSA structures at train time, tools like JackHMMER and HHBlits (tools for accurate distant homology detection) are used on large databases like Uniref90, BFD, Uniclust30, and MGnify. The output MSA’s are de-duplicated and stacked. The depth and diversity of MSAs significantly impact AlphaFold’s ability to infer residue interactions and folding patterns.
- Structural templates AlphaFold uses the Uniref MSA (above) to search PDB70 (a curated subset of PDB) using HHSearch to find homologous structures’ 3D atom co-ordinates ( along with residue interactions, and secondary structure annotations). This information fed as input to the network could help it deduce similar structures from highly related protein sequences. Note: During training, All template structures released after the primary input sequence are dropped, and templates that are too small are dropped.
2.1.2 Pre-pocessing the sequences during training
MSA features and pre-processing — Some data augmentation and space optimisation techniques are used to modify the MSA features:
- MSA Block deletion: During training contiguous blocks of sequences are deleted from the MSA, to generate diversity that removes whole branches of the phylogeny.
- MSA Clustering: The aim here is to reduce the number of sequences in the MSA () to ~128 (). First, a set of random sequences are selected as representatives. The remaining sequences are matched with their ‘nearest’ representative sequence, and used to generate a mini sequence profile. This profile is fed along with each representative sequence as input to the network so that all sequences not included still influence the final prediction.
- MSA masking: 15% of the amino acids in each cluster centre are masked — at each masking position, the amino acid is either (i) Replaced with a masking token (ii) Replaced with an amino acid at random, or sampled from the mini sequence profile distribution at that position.
- The residues dimension is cropped to a single contiguous region, and the final crop size is denoted by .
Template features and pre-processing —
- A Template distogram is created for the template structures. This is a one-hot pairwise feature indicating the pairwise distance between every one of the amino acids (beta carbons atoms) in the chain. The distance is binned into 38 intervals.
- Template torsion angles: The 3 backbone torsion angles and up to 4 side-chain torsion angles for each residue represented as sine and cosine encodings (more details on torsion angles in the structure modules)
Other additional features are listed in supplementary information section 1.2.9 of the Alphafold2 paper.
2.1.3 Input processing: Converting input information into embeddings

- Creating input embeddings: The primary input sequence (target_feat) is transformed with two linear embeddings and outer-summed to form a pairwise representation [, where ] . This is followed by addition with the original sequence converted to a relpos representation, that computes clipped relative positions between amino acids in the chain (equivalent to positional embeddings in sequence models). As a result, we have the initial pair representation of the input sequence .
The MSA features (msa_feat) also go through a linear layer, and added to a transformed represenation of the input sequence to form the initial MSA represenation.
- Integrating information from the templates: Next, template information is incorporated into both these embeddings. The template sequences and the torsionangles (contained in template_angle_feat) are transformed by linear layers and concatenated to the initial MSA representation. The template distogram related features (template_pair_feat) are embedded with a shallow attention network and added to the pairwise representation.
- Processing extra MSA features: The MSA features not selected as cluster centres () are processed by a shallow optimised Evoformer network and this is used to update the pairwise representation.
At the end of this processing stage, we have an MSA representation and a pairwise representation, both containing information about the original sequence as well as the template sequences.
Section 2.2: The Evoformer
Bird’s eye view of the Evoformer The main trunk of the network consists of Evoformer blocks that update the MSA representation and a pair representation . The MSA representation and the pairwise representation go through updates separately as well as incorporate information across each other, along with residual connections
The Evoformer uses attention-based mechanisms that allows it to dynamically learn interactions between non-neighboring nodes, and focus on computing the graph of how each residue relates to another [8].
Each of the 48 Evoformer blocks in the evoformer stack has an MSA tower and the pairwise representation tower (pictured horizontally below). The MSA representation is processed with axial self attention, and the pairwise representation is processed with triangular updates and triangular self attention. Both representations are also used to update each other. The MSA representation and the pairwise representation pass through the Evoformer stack times and are updated each time before the next cycle.

2.2.1 The MSA representation updates
The MSA representation undergoes row-wise and column-wise gated self attention, which are forms of axial self attention. Remember that the MSA representation is large because i.e., is huge — so axial attention factorizes the attention computation across the row and column dimension and is more efficient for high dimentional data.


- Row-wise gated self attention with pair bias: Each row is updated with self attention from all residues within the same row, with a bias from the pairwise representations (to maintain consistency between pairwise and MSA representations). This way, information flow happens between all residues of a single sequence and is used to update each sequence.
- The column-wise attention lets the elements that belong to the same target residue position exchange information. The column is updated with information from all other residues of the same column.
- Following this is an MSA transition layer, that expands and compresses the number of channels
2.2.2 Pairwise representation updates
Outer Product Mean: As a first step in this parallel branch, the MSA representation is incorporated into the pairwise representation. To do this, the MSA entries are linearly projected into a small dimension. Then for two ‘columns’ , the outer products of the vectors at each row are taken and averaged over the sequences. Finally, this matrix is flattened and linearly transformed to form the element at of the pairwise representation. This is a neat way of transforming the MSA representation into a similar dimension as the pairwise representation to be incorporate into the existing pairwise representation

A note on the triangular relationship constraints Since Alphafold’s pairwise representation is though to encode something akin to pairwise distances, a number of geometric constraints need to be enforced. Consider the pairwise representation. Each in the pair tensor encodes the relationship between positions i and j in the sequence. Assuming this eventually represents distances between the residues, we also want to indirectly encourage geometric constraints to be satisfied (the distance between residues ik and jk provide strong constraints on what distance ij can be by triangle inequality). To do this, we update the element (considered and ‘edge’) using the two other edges and of the ‘triangle’ formed using another residue (for all possible residues ). This update is done using a simple mathematical update as well as attention.
Triangular multiplicative updates: The triangle inequality is not enforced in the model but rather, it is encouraged through ensuring each position is updated by looking at all possible triplets of positions (i,j,k) at a time [6][9]. However if we were to anchor on a value k, remember that in the pairwise representation we have both and in the matrix, as well as and . Intuitively, apart from just encoding physical distances imagine these pairwise representations to also encode directional influences each residue may have on the other. To account for updates in all possible directions, Alphafold divides updates into two steps, “incoming edges” wrt k and “outgoing edges” wrt k (Figure 4c).

is updated based on and for all other atoms k for the “incoming edges” (incoming to i and j from k) triangular update.
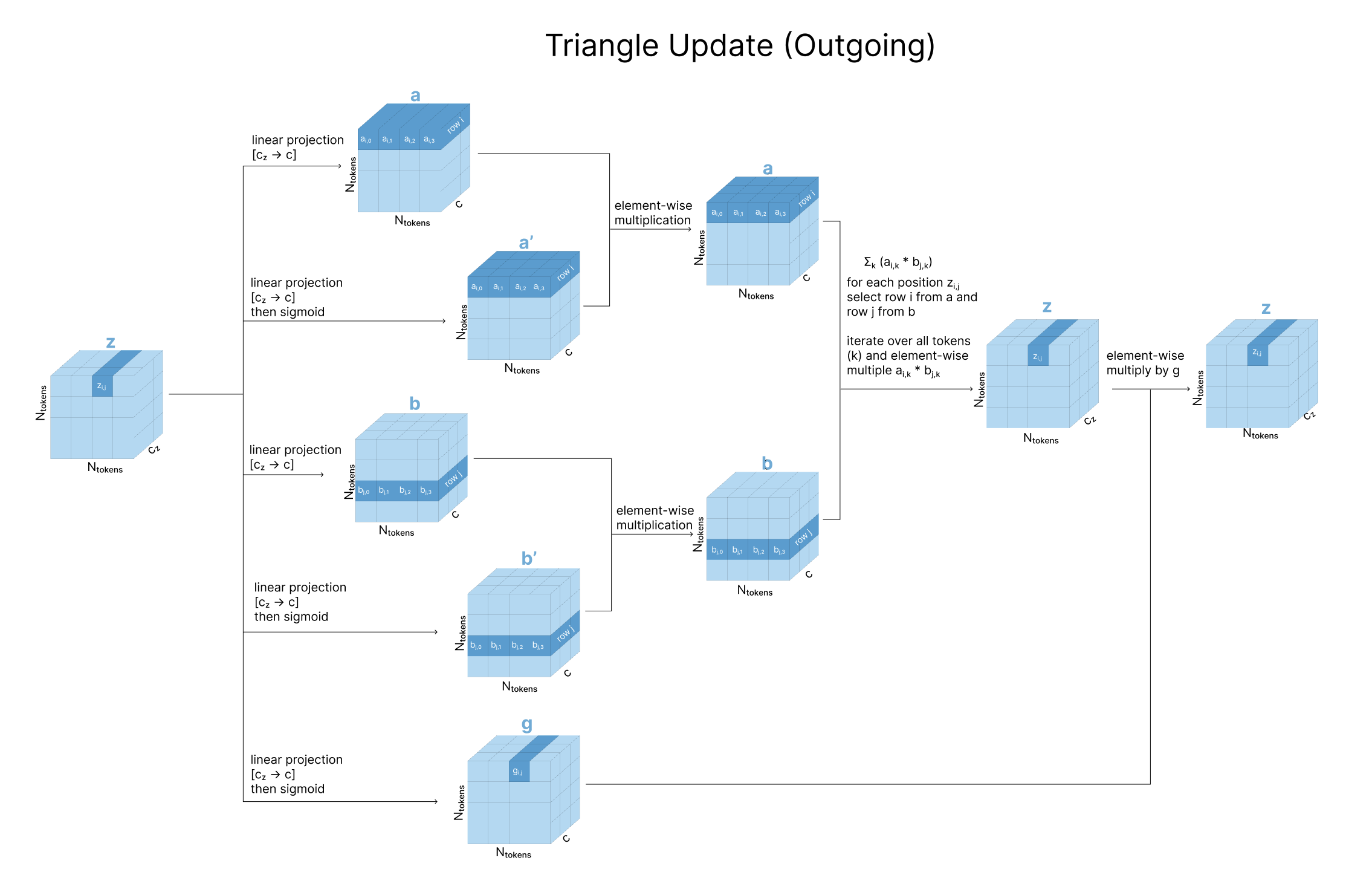
is updated based on and for all other atoms k for the “outgoing edges” triangular update
Triangle attention updates: Triangle attention incorporates the triangle principle to attention, updating by incorporating and for all atoms k.
Starting Node Triangle Attention Specifically, in the “starting node” case to calculate the attention scores for we want to find the influence of all other nodes on node (that is all ) biased by the influence node j on those same nodes.
Query
Keys, values
for all values of k
Bias
for all values of k (reduced to channel = 1 using linear projection)

Finally, the transition layer for the pairwise representation contains a 2-layer MLP where the intermediate number of channels expands the original number of channels by a factor of 4.
The final Evoformer block provides a highly processed MSA representation and a pair representation , which contain information required for the structure module and auxiliary network heads. The prediction modules are also using a “single” sequence representation where , and . This single representation is derived by a linear projection of the first row of the MSA representation . Remember that this first row actually contains the original input amino acid sequence updated by all other related sequances in the MSA & pairwise representation
Section 2.3: The Structure Module


2.3.1 Structure module Preliminaries
Alphafold2 was one of the first works to predict the backbone atom positions directly, rather than predict distances or correlations. To do this, the aminoacid residues are represented as a residue gas comprised of “backbone frames” (parametrized by ) and and “torsion angles” ().
What are “frames” here? Each residue backbone ‘frame’ is defined as the geometry of a triangle of “N (nitrogen) — (alpha carbon) — C (carbonyl carbon)” of each residue with respect to the global frame. Each frame is represented as an pair, . Here, is a rotation matrix of the frame and . These rotation and translation matrices help compute the location of the ‘frame’ or the rigid body, with respect to the global frame.
Each atom position in an amino acid residue can be determined by backbone torsion angles ( that signify positions of atoms other than , , C) and side chain trosion angles . (The bond length and bond angle is assumed to be almost always same ). This is represented in the network by where and .
As the single representation and the pairwise representation cycles through the structure modules, they are used to update the backbone frames and predict the Torsion angles.
2.3.2 Structure Module Architecture
The structure module takes as input (a) The single representation (b) The Pair representation and (c) the current estimate of the per-residue backbone frames. It updates the single representation using invariant point attention (incorporating the current estimates and the pair representation). Finally it predicts update frames (that can be composed with the backbone frames) and the torsion angles that indicate the side chain positions.

2.3.3 Invariant Point Attention Module
Alphafold uses a version of the iterative SE(3)-Transformer. The Iterative SE(3)-Transformer is a graph transformer with a customized attention mechanism designed to be equivariant under continuous 3D roto-translations — ie the output remains consistent even when the input is transformed by a global change. In Alphafold2, this mechanism is incorporated in the Invariant point attention — Attention between two residues on 3D space that is invariant to global transformations. The IPA module updates the abstract single representation using multiple “channels” of attention:
(1) It first computes the usual self-attention for the single representation (2) Then it converts the pair representation into a simple element-wise “pair bias” to incorporate into the attention module (3) Next, it converts the backbone frames into “distance affinities”, which can be thought of simply as representing distances. This serves two purposes: the attention between two points is determined based on the distance between the points. Additionally, this attention term is invariant to global transformations


Finally, it adds all of these to obtain a final set of attention weights, which are then combined with vector representations of each input type and summed for the final single representation update.

Any global rotation or translation cancels out in the “distance affinity” term, because the L2-norm of a vector is invariant under rigid transformations.
2.3.4 Structure module outputs
Backbone updates: The updates for the backbone frames are learnt from the (IPA updataed) single sequence representation
Prediction of the backbone frames and atom co-ordinates: The network predicts a quaternion for the rotation and a vector for the translation. A quaternion is a mathematical representation used to describe rotations in 3D space; A quaternion q consists of four components: q = (w, x, y, z) where w is a scalar component and (x, y, z) are Vector components representing rotation axis. This predicted quaternion is converted into a rotation matrix, and together with the translation, is applied to the backbone frames as an update (Supplementary section, Algorithm 23). Finally, the update frames are composed with the existing iteration of the backbone frames. To predict the atom co-ordinates, standard bond lengths and bond anlges are combined with the frame (corresponding to )
Conversion of the GT atom co-ordinates into frames: Given groundtruth coordinate locations of three points of the triangle (corresponding to ), the frames can be computed using the Gram-Schmidt process (Supplementary Algorithm 21).
Torsion angle prediction: The updated single representation is also used to predict the torsion angles where and using a shallow resnet.
Prediction of torsion angles and atom co-ordinates: Each angle gets mapped to points on the unit circle via normalization corresponding to rather than predicting the angle directly since to is a huge jump and might lead to instabilities compared to the sine and cosine that remains continuous. The predicted torsion angles are used to create update frames for the side chain (and other backbone) atoms. These transforms are applied starting from the global frame incrementally over each rigid body group with the geometric dependency order. Once the frames are applied, the standard bond lengths and bond angles of the rigid groups are applied to compute the final atom co-ordinates.
Updated single sequence representation : The single sequence representation from the Evoformer module, updated by applying IPA in the recursive blocks of the structure module.
2.4 The Final Network Outputs and Losses
The outputs of the network include
- The Co-ordinates of all residues and their atoms (2.3.4 above)
- PLDDT head — predicts the per-residue (pairwise) lDDT-C scores which is the intrinsic model accuracy / uncertainty estimates. This is predicted by taking the final single representation from the structure module, and projecting it into 50 bins (each bin covering a 2 lDDTC range) and applying softmax. To create targets while training, network uses the final strcture module prediction and computes the lDDT-C against the groundtruth.
- TM-score head — Predictor of the global superposition metric TM-score, a more accurate global similarity measure between two protein structures. In alphafold, this value is computed over all possible alignment single residue alignments that can be used to compute the pairwise distance between atoms. The model predicts a modfied term of this error metric by applying a linear layer and softmax over the single representation.
- Distogram predictions: The pairwise representation from the evoformer output is used to predict a distogram — pairwise matrix representing distance between each set of carbon atoms. The is symmetrised (by summing it with the trasnform) and a linear projection into 64 bins (with softmax) is applied to predict the distogram. The targets are computed from the ground truth atom positions, and converted to one-hot binned values for training.
- Masked MSA prediction: The final representation is also used to predict the masked values from the MSA representation (during pre-processing), similar to an MLM (masked language modelling) objective.
The network is trained with the gradients from the FAPE loss and a number of auxiliary losses.
- Frame Aligned Point Error (FAPE) Loss: Compares the predicted atom positions to the true positions under many different alignments. The final FAPE loss is computed over all backbone and side chain atoms. The loss between predicted atom position relative to frame and true atom position relative to is computed as an L2 norm for each atom. For each alignment, defined by aligning the predicted frame to the corresponding true frame, we compute the distance of all predicted atom positions from the true atom positions. The resulting distances are penalized with a clamped L1 loss.
- Torsion angle losses: The side chain and torsion angles are compared with the groundtruth torsion angles with an L2 loss in (points in a unit circle). This is mathematically equivalent to the raw angle difference.

[1] The Cell: A molecular approach
[2] 🔗 Protein Structure (Nature Scitable)
[3] 🔗 Protein Structure - LibreTexts
[4] 🔗 AlphaFold - DeepMind Blog
[5] 🔗 AlphaFold 2 - Blopig Blog
[6] 🔗 The Illustrated AlphaFold